Тестовая программа
После выполнения необходимых подключений пришло время подключить SD-карту. В коротком тестовом скетче отображает файлы, присутствующие на карте. Код можно взять ниже или в zip-файле в конце этой статьи как — sd_info.
#include <SPI.h>
#include <SD.h>
#define CS 8
Sd2Card card;
SdVolume volume;
SdFile root;
boolean initCard()
{
Serial.print("Connecting to SD card... ");
// Initialize the SD card
if(!card.init(SPI_HALF_SPEED, CS))
{
// An error occurred
Serial.println("\nError: Could not connect to SD card!");
Serial.println("- Is a card inserted?");
Serial.println("- Is the card formatted as FAT16/FAT32?");
Serial.println("- Is the CS pin correctly set?");
Serial.println("- Is the wiring correct?");
return false;
}
else
Serial.println("Done!");
return true;
}
void setup()
{
Serial.begin(9600);
if(!initCard())
while(1);
Serial.println("\n----------------");
Serial.println("---Basic Info---");
Serial.println("----------------");
Serial.print("An ");
switch (card.type())
{
case SD_CARD_TYPE_SD1:
Serial.print("SD1");
break;
case SD_CARD_TYPE_SD2:
Serial.print("SD2");
break;
case SD_CARD_TYPE_SDHC:
Serial.print("SDHC");
break;
default:
Serial.print("Unknown");
}
Serial.println(" type card got connected");
// Try to open the filesysten on the card
if(!volume.init(card))
{
Serial.println("Could not open / on the card!\nIs the card formatted as FAT16/32?");
while(1);
}
else
{
Serial.print("The inserted card is formatted as: FAT");
Serial.println(volume.fatType(), DEC);
Serial.print("And the card has a size of: ");
// Calculate the storage capacity of the volume
uint32_t cardSize = volume.blocksPerCluster() * volume.clusterCount();
Serial.print(cardSize / 2048);
Serial.println("MB!");
}
Serial.println("\n----------------");
Serial.println("--Stored files--");
Serial.println("----------------");
// Print a list of files that are present on the card
root.openRoot(volume);
root.ls(LS_R);
}
void loop(void) {
}
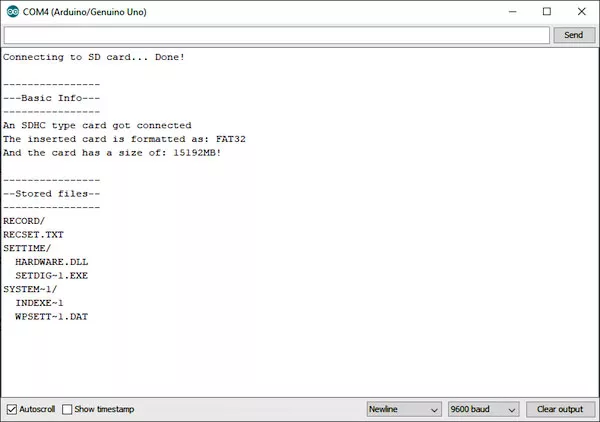
Как видите, большая часть кода обрабатывает вывод консоли. Всего несколько строк необходимо для подключения к устройству и инициализации файловой системы для чтения и записи файлов. В этом примере, однако, печатаются только некоторые основные свойства карты, такие как размер, тип и сохраненные файлы.
Другие полезные функции
Есть и другие полезные функции для работы с SD картой. Некоторые из них мы приведем ниже:
- Если вы хотите проверить наличие файла на носителе, используйте функцию SD.exists(«имя_файла.txt»), которая вернет значение true или false.
- Удалить файл можно с помощью функции SD.remove(«имя_файла.txt»). Но будьте аккуратны! Файл удалиться полностью. Никакой «корзины» или резервной копии для восстановления не останется.
- Создать подпапку можно с помощью функции SD.mkdir(«/имя_новой_папки»). Очень удобно для структуризации ваших данных на начальном уровне. Если папка с таким именем уже существует, ничего не произойдет. Не забывайте, что вы можете воспользоваться функцией SD.exists() перед созданием папки для проверки.
Несколько полезных функций для работы с файлами:
- Для перемещения указателя при считывании/записи файла, используется функция seek(). Например, запись функции в виде seek(0) переместит вас в начало файла.
- Функция position() позволит вам узнать, где именно вы находитесь в пределах файла на данный момент.
- Функция size() выведет вам информацию о размере файла в байтах.
- Узнать, является ли файл на карте директорией можно вызвав функцию isDirectory().
- Последовательная работа с файлами, которые находятся в папке реализуется с помощью вызова функции openNextFile().
- Возможно, вам понадобится имя файла. Например, если вы вызвали следующий файл в папке с помощью openNextFile(). В этом случае можно воспользоваться функцией name(), которая вернет массив символьных данных, которые можно отобразить непосредственно в серийном мониторе Arduino IDE с помощью Serial.print().
Интеграция проекта
Элементы проекта, такие как scope, график проекта, его стоимость, риск и качество являются взаимозависимыми. Небольшое изменение одного из них может оказать большое влияние на другие части вашего проекта.
Интеграция проекта – это действия по координации элементов проекта и их компромисс для достижения целей вашего проекта. Интеграция означает интегрировать части в одно целое. Ваша первая задача по управлению интеграцией возникает в самом начале проекта – разработка его устава.
Устав проекта содержит обзор проекта и его необходимость. Здесь можно увидеть уровень полномочий менеджера проекта. Устав проекта, как правило, включает начальный объем (scope), смету расходов, график реализации и список заинтересованных сторон проекта.
План проекта является воплощением интеграции проекта. Это дорожная карта, которую вы используете, чтобы направлять ваш проект по ходу его реализации, а также это тот базовый уровень, с которым вы сравниваете прогресс после начала работы над проектом.
Когда вы закончите планирование, приходит время воплотить этот план в жизнь, руководя реализацией проекта. Это тот этап, где все элементы начинают выполнять работу над проектом.
Говоря о мониторинге и контроле работы над проектом, здесь вы сравниваете прогресс с вашим планом. Таким образом, вы можете решить, что вам нужно сделать, чтобы ваш проект шел в нужное русло, как перераспределять ресурсы, идти на компромисс с целями и идти на компромиссы между объемом, временем, стоимостью и качеством.
Изменения могут оказать существенное влияние на проекты, поэтому вы хотите, чтобы изменения происходили контролируемым образом. Благодаря управлению изменениями у вас есть процессы, позволяющие просматривать запросы на изменения, утверждать или отклонять их и управлять ими до тех пор, пока они не будут выполнены.
Последнее, что вы делаете в управлении интеграцией – закрываете проект. То есть вы завершили все, что происходило в проекте, чтобы формально завершить его. Когда вы закрываете проект, вы просматриваете всю информацию, которую вы собрали о проекте, чтобы убедиться, что все работы по проекту завершены и цели достигнуты.
Перейти к следующей части «Инициация проекта».
Переход от монолита к микросервисам
Теперь хочется поговорить, как переходить от монолита к микросервисам, если вы решили, что это действительно то, что нужно. Итак, у вас есть большой монолит. Как теперь делить его на части?
Вы вынимаете нечто, ограниченное по бизнес-логике (то, что называется ограниченным контекстом в DDD). Конечно, для этого придется понять монолит. Например, хороший кандидат на выделение в отдельный сервис — часть монолита, которая требует частых изменений. Благодаря этому, вы получаете незамедлительную выгоду от выделения сервсиа — не придется тестировать монолит часто. Также хорошо выделять в отдельный сервис то, что доставляет наибольшее количество проблем и плохо работает.
Когда вы разделяете монолит на сервисы, обращайте внимание, как у вас структурированы команды. Ведь есть эмпирический закон Конвея (Conway’s law), который говорит, что структура вашего приложения повторяет структуру вашей организации
Если ваша организация построена на технологических иерархиях, построить микросервисную архитектуру будет очень трудно. Поэтому нужно выделить feature-команды, которые будут иметь все необходимые навыки, чтобы написать нужную логику от начала до конца.
На самом деле, редко бывает, что у нас чистая микросервисная архитектура. Чаще всего мы имеем нечто среднее между монолитом и микросервисами. Обычно есть какой-то большой исторически сложившийся код, и мы понемногу стараемся распутывать его и отделять от него части.
Если же мы делаем проект с нуля, нужно выбрать — монолит или микросервисы?
Монолит лучше выбирать в следующих случаях:
- Если у вас новый домен и/или нет знаний в этом домене..
- Если вы делаете прототип или быстрое решение.
- Если команда не очень квалифицированная (все начинающие, например).
- Если вам требуется просто написать код и забыть о нем.
- Если мало денег на проект — микросервисы обойдутся дорого.
Микросервисы лучше выбрать, если:
- Точно понадобится линейное масштабирование.
- Вы понимаете бизнес-домен, сможете выделить ограниченный контекст и сможете обеспечить согласованность на бизнес-уровне.
- Команда высококвалифицированная, есть опыт и пара загубленных проектов с микросервисами в прошлом (все равно с первого раза сделать микросервисы не выходит).
- Предстоит долгосрочное сотрудничество с заказчиком.
- Достаточно средств для инвестирования в инфраструктуру.
Микросервисы: «за» и «против»
Преимущества:
Микросервисный подход можно применить, даже если вы не будете использовать Message Bus, и микросервисы будут логическими. Ведь, с точки зрения развертывания, здесь возможно многообразие. Если говорить в терминах .NET, вы сможете разворачивать сервисы даже в рамках одного домена приложения. У вас будут всего лишь изолированные модули, которые взаимодействуют с помощью обмена сквозь память. Будет работать действительно быстро, при этом не будет накладных сетевых расходов.
Четкое модульное деление. Позволит усилить модульную структуру — в вашей команде будут люди, которые прекрасно знают, как работает та или иная часть кода
Это особенно важно для больших команд разработчиков. Высокая доступность
Сервисы могут работать не все — при этом все остальное будет работать.
Разнообразие технологий, или возможность использовать правильный инструмент. Например, если нужно построить хранилище данных, вы подберете тот инструмент, который действительно умеет хранить большие объемы данных и быстро их выбирать. Микросервисы позволяют даже просто опробовать технологию на каком-нибудь сервисе, и это не повлияет на другие сервисы, т. к. контракт изолирован через сетевое взаимодействие.
Независимое развертывание из-за слабой связанности сервисов: простые сервисы проще разворачивать, и меньше вероятность отказа системы.
Недостатки:
- Сложность разработки.
- Конечная согласованность — бизнес вашего заказчика должен позволять работать с отложенными данными. Этим придется платить за высокую доступность. Классический пример конечной согласованности — банковские карты, транзакции между которыми могут занимать дня три. Из-за этого есть вероятность превышения кредитного лимита, и тогда начинает действовать простейший механизм компенсации — вам звонят из банка с просьбой погасить превышение.
- Сложность операционной поддержки — нужны грамотные DevOps-инженеры, непрерывное развертывание и автоматический мониторинг. Без всего этого микросервисы использовать не следует.
Немного о мониторинге и тестировании мироксервисной системы
Есть инструменты, которые позволяют развертывать такую систему и следить за ней, например, ZooKeeper, который решает проблему конфигурирования за нас. Также есть такие инструменты типа Logstash, Kibana, Elastic, Serilog, Amazon Cloud Watch. Все они следят за вашими сервисами.
Как тестировать микросервисную систему? Я вижу это следующим образом. У вас есть сервис, который решает какую-то бизнес-задачу. Ваша цель — протестировать его бизнес-контракты. Большинство тестов, которые вы делаете — модульные, которые для кода, написанного в рамках этого сервиса. Это — низ пирамиды тестирования. Следующий уровень — интеграционное тестирование, которое проверяет, как этот сервис отвечает на стандартные запросы. Тут у вас огромное пространство для интеграционного тестирования кода, написанного изолированно. Следующий этап — использование разных инструментов, чтобы гарантировать, что контракт не поменялся. В нашем проекте мы использовали Swagger, который позволяет зафиксировать контракт.
Управление изменениями в проекте
Во время планирования вы создали планы для управления коммуникациями, изменениями и качеством. Теперь, когда проект в стадии реализации, пришло время воплотить эти планы в жизнь.
Для начала, вы и ваша команда переводите коммуникацию из плана в действие. Каждый создает и отправляет информацию, а также извлекает и хранит любую поступающую информацию, и все это в соответствии с планом. И пока вы общаетесь, не забывайте, что вам также необходимо реализовать план управления заинтересованными сторонами, чтобы поддерживать проект.

Давайте поговорим об отчетах. Например, обычная отправка отчетов о состоянии раз в неделю. Они обычно включают в себя то, что произошло, работу, которая была запланирована, работу, которая была завершена, и работу, которая шла не по плану. Укажите любые отклонения и способы их исправления. Кроме того, укажите проблемы, а также шаги, которые вы планируете предпринять для их решения. Наконец, составьте и распространите отчеты о достижениях за эту неделю.
Для команды управления проектом вы можете подготовить сводный отчет о его статусе. Таким образом, они смогут сосредоточиться на общей картине проекта. Если они попросят подробностей, вы можете составить дополнительные отчеты.
Информационные панели отображают информацию в графическом виде и позволяют легче увидеть, что происходит с реализацией проекта. Например, вы можете отмечать прогресс или производительность с помощью стоп-сигналов. Зеленый цвет говорит, что все в порядке. Желтый указывает на небольшое отклонение, а красный цвет указывает на более серьезную проблему.
Во время процесса обмена сообщениями вам нужно следить за тем, как все это работает. Получают ли заинтересованные стороны нужную информацию, когда она им нужна, и используются ли лучшие методы? Если это не так, измените план коммуникации, чтобы отразить то, что они хотят.
Теперь об управлении изменениями. При поступлении запросов на изменение следуйте инструкциям в плане управления изменениями, чтобы определить, следует ли добавлять их в проект. Вы добавляете каждый запрос на изменение в созданный журнал запросов на изменение, чтобы вы могли отслеживать запрос, был ли он отклонен комиссией по обзору изменений или одобрен и добавлен в проект.
Кроме того, если добавленные запросы на изменение влияют на график и/или стоимость, обновите базовый план, чтобы отразить эти корректировки. Таким образом, запросы на изменение не создают расхождений между планом и фактической производительностью.
Вы также выполняете действия для измерения качества и оценки уровня качества, обеспечиваемого вашим проектом. Как вы указали в плане управления качеством, если качество не находится на требуемом уровне, выясните, как его улучшить. Даже если вы получаете должное качество, пересмотрите свои процессы, так как всегда есть возможность добиться соответствующего качества меньшими силами и затратами.
Помните, что управление коммуникациями, изменениями и качеством – это не разовые усилия. Во время выполнения проекта постоянно отслеживайте обмен данными, отслеживайте запросы на изменения и измеряйте качество. Если вы будете в курсе всего этого, вы сможете реализовать свой проект более успешно и с меньшим драматизмом.
Что такое робот и что он умеет
С точки зрения участия в бизнес-процессах компании робот – это виртуальный сотрудник-оператор. Вот как живой, только:
У него идеальная память
Он ничего не забудет и не перепутает.
Он всегда на работе
Ночные запуски – без проблем.
Когда дело доходит до череды кликов или набора текста, его скорость впечатляет
Но рано вешать ярлыки «робот все выполнит в N раз быстрее человека»: если в приложении отчет формируется 5 минут – робот не заставит его работать быстрее.
Ему ближе, чем человеку, программный вызов сервисов, приложений и процедур
Мы можем распаковать архив, открыв его в менеджере архивов, а можем использовать консольную команду – второй вариант будет гораздо быстрее. Робот тоже может использовать команды, только еще эффективнее, и этот фокус проходит не только с архивами.
Он однозадачен
Мы постоянно переключаемся между задачами, отвлекаемся, отвечаем на телефонные звонки. Робот так не умеет, он приступит к выполнению следующего сценария в очереди не раньше, чем завершит текущий. Распределять загрузку между роботами можно и нужно, но за фразой «выполнение запустится по такому-то условию» всегда прячется приписка «если робот не занят выполнением другой задачи». Заказчикам необходимо смириться с этим фактом и не ждать моментальной реакции на сигнал к запуску.
Он оперирует формальной логикой:
У робота напрочь отсутствует интуиция
Человек при поиске файла с названием «Отчет за дату ДДММГГ.xlsx» интуитивно поймет, что файл «Отчет за дату 120220 (исправлено).xlsx» ему тоже подходит, а разницу в названии с файлом «Отчет за дату 120220 .xlsx» он даже вряд ли заметит. Робот же последние два файла определит как неподходящие под маску. Можно смягчить условия поиска, но стоит ли обрабатывать файл «Отчет за дату 120220 Переделать!.xlsx»?
Робот не стремится достичь какой-либо определенной цели
Он просто выполняет то, что явно задано сценарием, не обращая внимания ни на какие непредусмотренные сигналы и события. Робот считает сценарий успешно завершенным, если ему удалось выполнить все заложенные в него шаги
Неважно, сколько сообщений об ошибках будет на экране, если они не блокируют выполнение шагов сценария или робот специально не обучен их «отлавливать». Важный вывод из этого пункта: в изменяющихся условиях формально успешное выполнение сценария не гарантирует корректный бизнес-результат! Этот результат необходимо своевременно контролировать – хорошо, если это происходит естественным образом при его обработке на последующих этапах процесса
У сотрудника-оператора есть старший сотрудник или начальник, к которому можно обратиться при возникновении непредвиденных ситуаций. Для робота тоже должны быть такие кураторы по каждому процессу.
Сотрудник работает на своем ПК или в терминальной сессии, каждый робот также работает в своем собственном окружении. Если бы и можно было запустить в одной сессии несколько роботов, это привело бы к печальным последствиям: попробуйте с коллегой подключить к одному компьютеру две клавиатуры и набирать каждый свой текст.
С точки зрения автоматизируемых приложений робот – это обычный пользователь, который нажимает на кнопки, вводит и считывает данные. Если приложение лицензируется по количеству одновременных подключений – робот займет лицензию при работе в нем.
Помимо взаимодействия с экранными формами приложений, роботы на используемой мной платформе умеют:
- извлекать и преобразовывать данные
- выполнять операции с файлами и папками
- запускать и останавливать приложения
- читать и записывать некоторые типы файлов без помощи приложений
- распознавать тексты со скан-копий (OCR)
- выполнять некоторые операции в офисных приложениях командами, без использования экранных форм
- запускать сценарии PowerShell и макросы VBA
- напрямую работать с почтовыми ящиками
- направлять HTTP и SOAP запросы
- обращаться к базам данных
- взаимодействовать с пользователем в той же сессии при помощи диалоговых окон
- выполнять вставки кода
- и многое другое.
Существует и альтернативная форма использования – виртуальный помощник: робот запущен в окружении реального пользователя, который при необходимости запускает тот или иной сценарий, или робот сам реагирует на наступление предусмотренного события. Напоминает использование макросов, только для разработки подобных сценариев не требуются специальные навыки (зато требуются лицензии RPA).
Планирование потоков
Для того чтобы понимать, в каком порядке исполнять код различных потоков, необходима организация планирования тих потоков. Ведь система может иметь как одно ядро, так и несколько. Как иметь эмуляцию двух ядер на одном так и не иметь такой эмуляции. На каждом из ядер: железных или же эмулированных необходимо исполнять как один поток, так и несколько. В конце концов система может работать в режиме виртуализации: в облаке, в виртуальной машине, песочнице в рамках другой операционной системы. Поэтому мы в обязательном порядке рассмотрим планирование потоков Windows. Это — настолько важная часть материала по многопоточке, что без его понимания многопоточка не встанет на своё место в нашей голове никоим образом.
Итак, начнём. Организация планирования в операционной системе Windows является: гибридной. С одной стороны моделируются условия вытесняющей многозадачности, когда операционная система сама решает, когда и на основе каких условия вытеснить потоки. С другой стороны — кооперативной многозадачности, когда потоки сами решают, когда они всё сделали и можно переключаться на следующий (UMS планировщик). Режим вытесняющей многозадачности является приоритетным, т.к. решает, что будет исполняться на основе приоритетов. Почему так? Потому что у каждого потока есть свой приоритет и операционная система планирует к исполнению более приоритетные потоки. А вытесняющей потому, что если возникает более приоритетный поток, он вытесняет тот, который сейчас исполнялся. Однако во многих случаях это бы означало, что часть потоков никогда не доберется до исполнения. Поэтому в операционной системе есть много механик, позволяющих потокам, которым необходимо время на исполнение его получить несмотря на свой более низкий по сравнению с остальными, приоритет.
Уровни приоритета
Windows имеет 32 уровня приоритета (0-31)
- 1 уровень (00 — 00) — это Zero Page Thread;
- 15 уровней (01 — 15) — обычные динамические приоритеты;
- 16 уровней (16 — 31) — реального времени.
Самый низкий приоритет имеет Zero Page Thread. Это — специальный поток операционной системы, который обнуляет страницы оперативной памяти, вычищая тем самым данные, которые там находились, но более не нужны, т.к. страница была освобождена. Необходимо это по одной простой причине: когда приложение освобождает память, оно может ненароком отдать кому-то чувствительные данные. Личные данные, пароли, что-то ещё. Поэтому как операционная система так и runtime языков программирования (а у нас — .NET CLR) обнуляют получаемые участки памяти. Если операционная система понимает, что заняться особо нечем: потоки либо стоят в блокировке в ожидании чего-либо либо нет потоков, которые исполняются, то она запускает самый низко приоритетный поток: поток обнуления памяти. Если она не доберется этим потоком до каких-либо участков, не страшно: их обнулят по требованию. Когда их запросят. Но если есть время, почему бы это не сделать заранее?
Продолжая говорить о том, что к нам не относится, стоит отметить приоритеты реального времени, которые когда-то давным-давно таковыми являлись, но быстро потеряли свой статус приоритетов реального времени и от этого статуса осталось лишь название. Другими словами, Real Time приоритеты на самом деле не являются таковыми. Они являются приоритетами с исключительно высоким значением приоритета. Т.е. если операционная система будет по какой-то причине повышать приоритет потока с приоритетом из динамической группы (об этом — позже, но, например, потому, что потоку освободили блокировку) и при этом значение до повышения было равно , то повысить приоритет операционная система не сможет: следующее значение равно , а оно — из диапазона реального времени. Туда повышать такими вот «твиками» нельзя.
Монолитные приложения и их проблемы
Все прекрасно знают, что такое монолитное приложение: все мы делали такие двух- или трехслойные приложения с классической архитектурой:
Для маленьких и простых приложений такая архитектура работает прекрасно, но, допустим, вы хотите улучшить приложение, добавляя в него новые сервисы и логику. Возможно, у вас даже есть другое приложение, которое работает с теми же данными (например, мобильный клиент), тогда архитектура приложения немного поменяется:
Так или иначе, по мере роста и развития приложения, вы сталкиваетесь с проблемами монолитных архитектур:
- сложность системы постоянно растет;
- поддерживать ее все сложнее и сложнее;
- разобраться в ней трудно — особенно если система переходила из поколения в поколение, логика забывалась, люди уходили и приходили, а комментариев и тестов нет);
- много ошибок;
- мало тестов — монолит не разобрать и не протестировать, поэтому обычно есть только UI-тесты, поддержка которых обычно занимает много времени;
- дорого вносить изменения;
- застревание на технологиях (например, я работал в компании, где с 2003 г. технологии до сих пор не изменились).
Рано или поздно вы понимаете, что уже ничего не можете сделать со своей монолитной системой. Заказчик, конечно, разочарован: он не понимает, почему добавление простейшей функции требует нескольких недель разработки, а затем стабилизации, тестирования и т. д. Наверняка многие знакомы с этими проблемами.
Характеристики
широко известной статьеФаулерЛьюис
Что такое микросервис?
определением Эдриана Кокрофтамикросервисы должны
- дёшево заменяться;
- быстро масштабироваться;
- быть устойчивыми к сбоям;
- никоим образом не замедлять нашу работу.
Насколько велик микросервис?
настолько большим, чтобы умещаться в рукеописывает случаисоотношение количества сотрудников и сервисовФред Джордж полагаетмикросервис должен соответствовать ограниченному контексту, который способен полностью понять один человекв Netflix их около 800Фред ДжорджРебекка Парсонспри разработке микросервисов труднее всего определять их границы
Компонентное представление через сервисы
- Компонент — это элемент системы, который можно независимо заменить, усовершенствовать (Мартин Фаулер) и масштабировать (Ребекка Парсонс).
- При разработке ПО мы используем два типа компонентов:
А. Библиотеки: куски кода, применяемые в приложениях, которые могут дополняться или заменяться другими библиотеками, желательно без воздействия на остальную часть приложения. Взаимодействие происходит через языковые конструкты. Однако если интересующая нас библиотека написана на другом языке, мы не можем использовать этот компонент.
Б. Сервисы: части приложений, по факту представляющие собой маленькие приложения, выполняющиеся в собственных процессах. Взаимодействие выполняется за счёт межпроцессной связи, вызовов веб-сервисов, очереди сообщений и т. д. Мы можем использовать сервис, написанный на другом языке, поскольку он выполняется в собственном процессе (этот подход предпочитает Чед Фаулер). - Независимая масштабируемость — каждый сервис может быть масштабирован независимо от остального приложения.
Гетерогенность
Мартин ФаулерЧед Фаулердолжны
- Предотвращает возникновение тесных связей благодаря использованию разных языков.
- Разработчики могут экспериментировать с технологиями, что повышает их собственную ценность и позволяет не уходить в другие компании, чтобы попробовать новинки.
Правило. При экспериментах с новыми технологиями:
— нужно использовать маленькие элементы кода (code unit), модули/микросервисы, чтобы снизить риск;
— элементы кода должны быть одноразовыми (disposable).
Автоматизация инфраструктуры
Непрерывное развёртываниеМартин ФаулерРебекка ПарсонсЧед ФаулерЭрик Эванс
- «Голубое» и «зелёное» развёртывание: нулевое время простоя.
- Автоматизация: нажатием одной кнопки можно развернуть несколько серверов.
- Серверы Phoenix: быстрый запуск и остановка.
- Мониторинг: можно заметить, когда что-то пошло не так, и отладить.
Архитектура с эволюционным развитием
- Превратить (рефакторить) единое приложение в приложение микросервисное, изолировав и перенеся наборы бизнес-логики (ограниченные контексты) в отдельные микросервисы.
- Объединить существующие микросервисы, например когда часто приходится одновременно изменять разные микросервисы.
- Разделить существующие микросервисы, когда нужно и есть возможность развивать их по отдельности или когда мы понимаем, что разделение серьёзно повлияет на бизнес-логику.
- Временно добавить в приложение какую-то возможность, создав микросервис, который будет работать определённое время.





